Программирование ITmozg:
23 Sep в 00:10
70 лет назад в этом месяце исследователи запустили первую программу на языке FORTRAN, что считается началом программирования общего назначения.
? @itmozg

13 Sep в 06:40
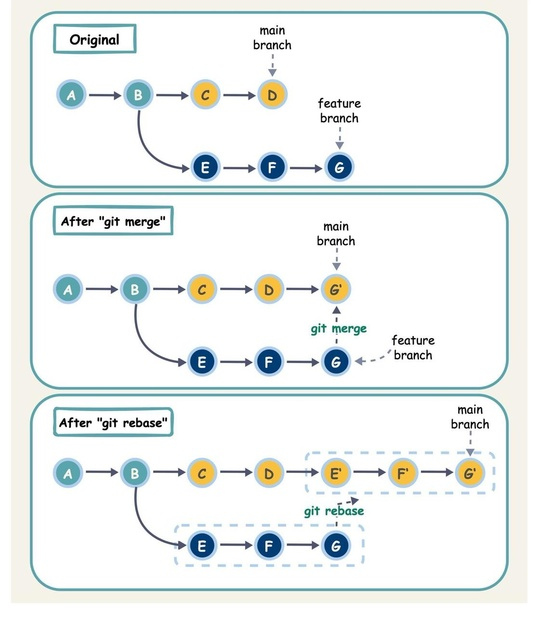
Git Merge vs. Rebase vs. Squash Commit
В чем разница?
Когда мы объединяем изменения из одной ветки Git в другую, мы можем использовать «git merge» или «git rebase». Диаграмма ниже показывает, как работают эти две команды.
Git Merge
Эта команда создает новый коммит G’ в основной ветке. G’ связывает историю обеих веток: основной и функциональной.
Git merge — это недеструктивная операция. Она добавляет новый коммит в основную ветку, не изменяя существующие коммиты в обеих ветках.
Git Rebase
Git rebase переносит историю коммитов функциональной ветки на конец основной ветки. Он создает новые коммиты E’, F’ и G’ для каждого коммита в функциональной ветке.
Преимущество rebase в том, что он создает линейную историю коммитов.
Однако будьте осторожны: следуйте золотому правилу Git Rebase — никогда не используйте его на общих ветках, чтобы избежать путаницы среди ваших коллег.
Git Squash Commit
Сквошинг сжимает несколько коммитов в один, упрощая историю коммитов.
? @itmozg
4 Sep в 20:00
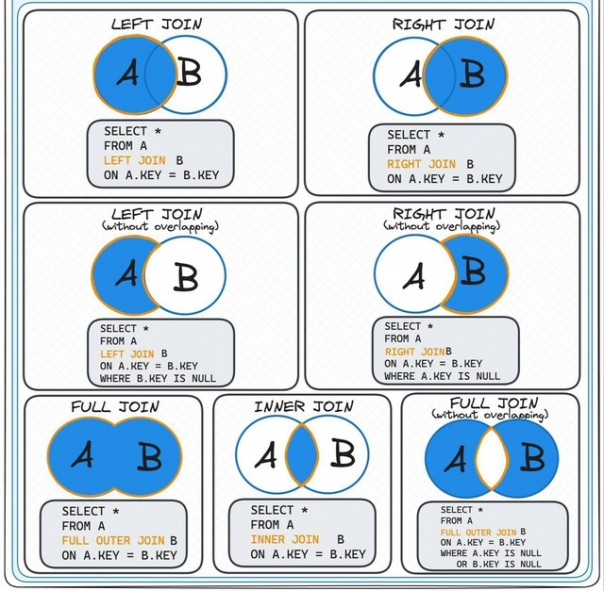
Наглядное объяснение джоинов SQL
#db
? @itmozg
4 Sep в 20:00
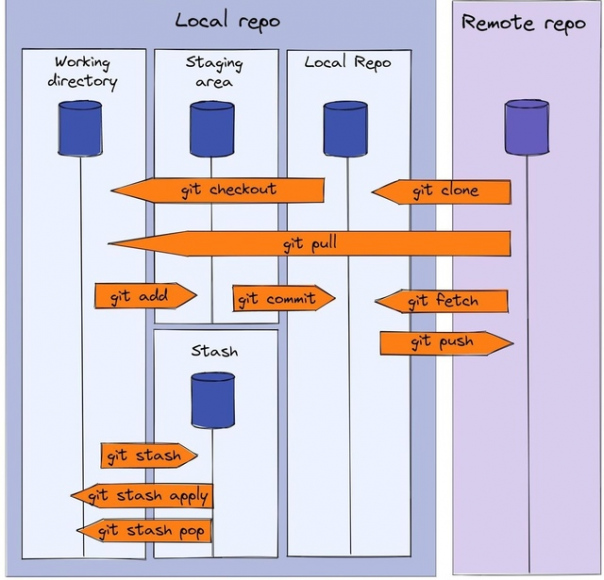
Git
? @itmozg
30 Aug в 20:20
Шпаргалка по SQL
#db
? @itmozg

30 Aug в 20:20
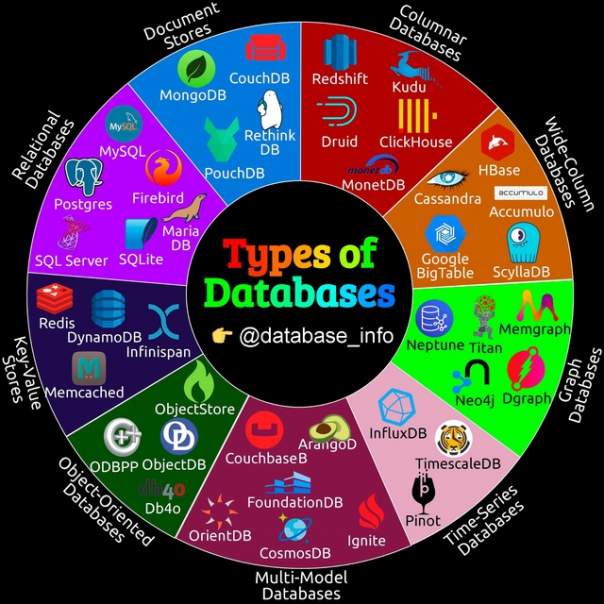
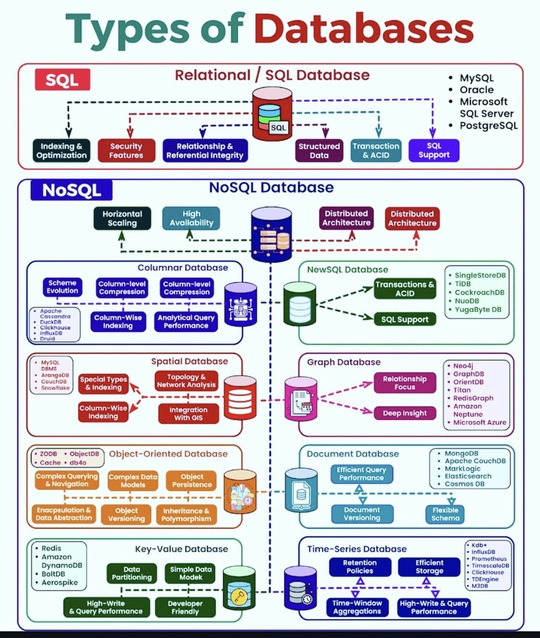
? Типы баз данных
#db
? @itmozg
30 Aug в 20:20
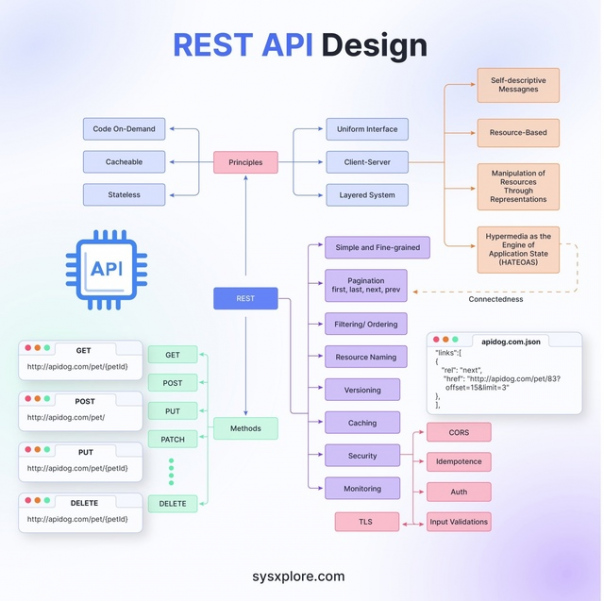
REST API Design
? @itmozg
25 Aug в 04:20
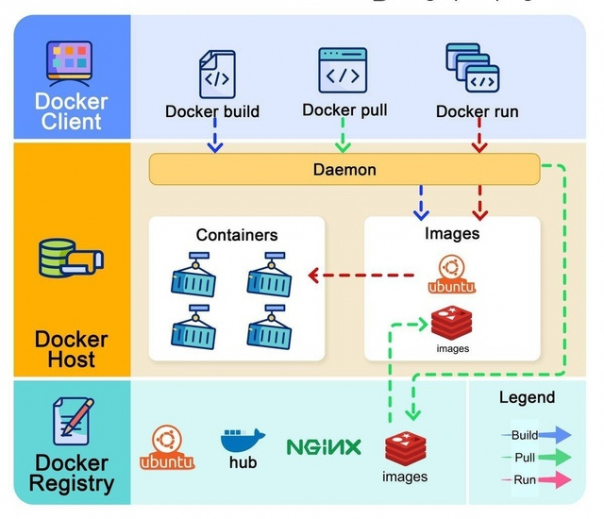
Как работает Docker?
Архитектура Docker состоит из трех основных компонентов:
? Docker Client
Это интерфейс, через который взаимодействуют пользователи. Он взаимодействует с Docker daemon.
? Docker Host
Здесь Docker daemon принимает запросы Docker API и управляет различными объектами Docker, включая образы, контейнеры, сети и тома.
? Docker Registry
Здесь хранятся образы Docker. Docker Hub, например, является широко используемым public registry.
? @itmozg
25 Aug в 04:20
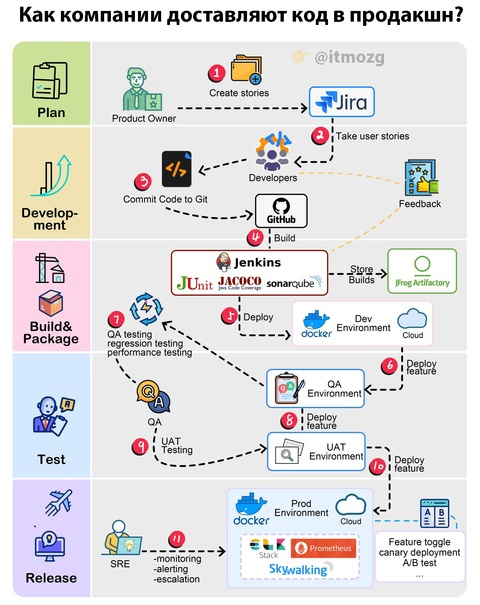
Как компании доставляют код в продакшн?
Ниже описан типичный процесс доставки программного обеспечения. В разных компаниях используются разнообразные инструменты и среды, поэтому это один из вариантов рабочего процесса, который демонстрирует некоторые общие практики. Подробности могут отличаться в зависимости от организации. Учитывая это, общие шаги выглядят следующим образом:
Шаг 1: Владелец продукта создает требования и пользовательские истории.
Шаг 2: Команда разработчиков определяет приоритеты для историй и организует спринты.
Шаг 3: Разработчики коммитят код в систему контроля версий.
Шаг 4: Сервер автоматизации собирает код и запускает тесты. Проводятся проверки покрытия кода и качества.
Шаг 5: Если сборка успешна, артефакты сохраняются в репозитории артефактов. Сборка затем разворачивается в среде разработчиков.
Шаг 6: Функции тестируются независимо в нескольких изолированных средах.
Шаг 7: Команда QA тестирует функции в средах для контроля качества. Проводятся различные виды тестирования.
Шаг 8: После проверки сборка разворачивается в среде для тестирования пользовательского принятия для окончательной валидации.
Шаг 9: Кандидаты на релиз, успешно прошедшие тестирование, могут быть развернуты в продакшене согласно графику выпуска. Для управления рисками используются фиче-флаги и методы постепенного развертывания.
Шаг 10: Команда по надежности сайта (SRE) мониторит продакшен и сообщает о проблемах. Команды приоритизируют и исправляют проблемы в соответствии с определенными политиками.
? @itmozg
25 Aug в 04:20
Базы данных классифицируются в первую очередь по методу организации данных, способу их поиска и хранения, производительности при доступе к данным и способности распределять данные по нескольким узлам для повышения доступности и устойчивости
#db
? @itmozg