25 Aug в 04:20
Как компании доставляют код в продакшн?
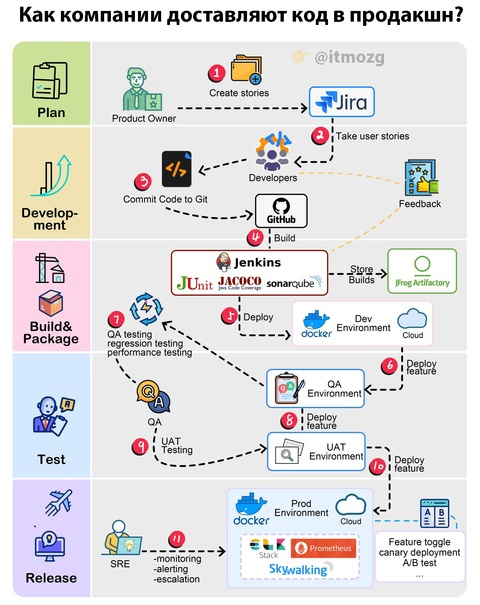
Ниже описан типичный процесс доставки программного обеспечения. В разных компаниях используются разнообразные инструменты и среды, поэтому это один из вариантов рабочего процесса, который демонстрирует некоторые общие практики. Подробности могут отличаться в зависимости от организации. Учитывая это, общие шаги выглядят следующим образом:
Шаг 1: Владелец продукта создает требования и пользовательские истории.
Шаг 2: Команда разработчиков определяет приоритеты для историй и организует спринты.
Шаг 3: Разработчики коммитят код в систему контроля версий.
Шаг 4: Сервер автоматизации собирает код и запускает тесты. Проводятся проверки покрытия кода и качества.
Шаг 5: Если сборка успешна, артефакты сохраняются в репозитории артефактов. Сборка затем разворачивается в среде разработчиков.
Шаг 6: Функции тестируются независимо в нескольких изолированных средах.
Шаг 7: Команда QA тестирует функции в средах для контроля качества. Проводятся различные виды тестирования.
Шаг 8: После проверки сборка разворачивается в среде для тестирования пользовательского принятия для окончательной валидации.
Шаг 9: Кандидаты на релиз, успешно прошедшие тестирование, могут быть развернуты в продакшене согласно графику выпуска. Для управления рисками используются фиче-флаги и методы постепенного развертывания.
Шаг 10: Команда по надежности сайта (SRE) мониторит продакшен и сообщает о проблемах. Команды приоритизируют и исправляют проблемы в соответствии с определенными политиками.
? @itmozg
Другие записи сообщества
4 Sep в 20:00
Git
? @itmozg
30 Aug в 20:20
Шпаргалка по SQL
#db
? @itmozg

30 Aug в 20:20
? Типы баз данных
#db
? @itmozg
30 Aug в 20:20
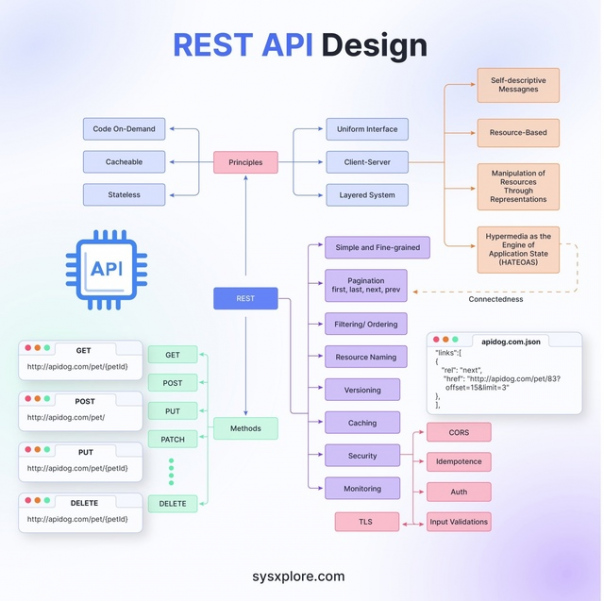
REST API Design
? @itmozg
25 Aug в 04:20
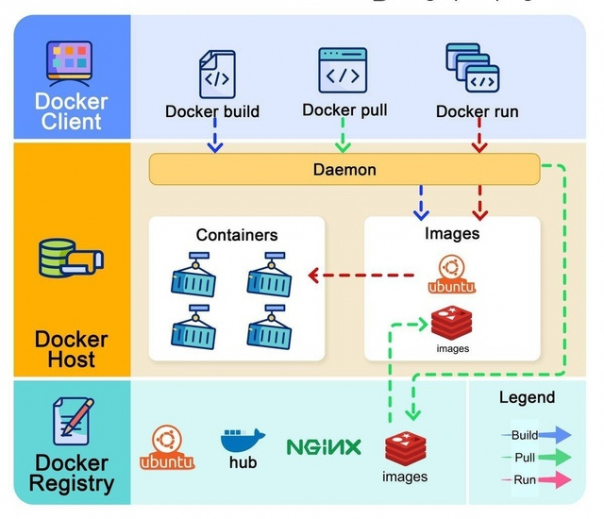
Как работает Docker?
Архитектура Docker состоит из трех основных компонентов:
? Docker Client
Это интерфейс, через который взаимодействуют пользователи. Он взаимодействует с Docker daemon.
? Docker Host
Здесь Docker daemon принимает запросы Docker API и управляет различными объектами Docker, включая образы, контейнеры, сети и тома.
? Docker Registry
Здесь хранятся образы Docker. Docker Hub, например, является широко используемым public registry.
? @itmozg
25 Aug в 04:20
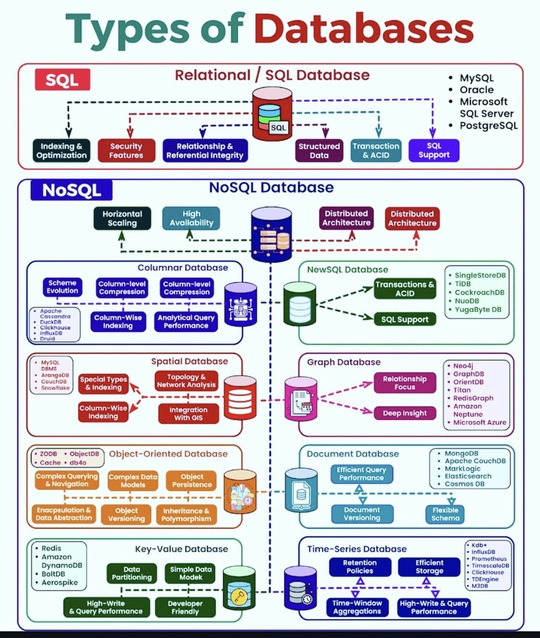
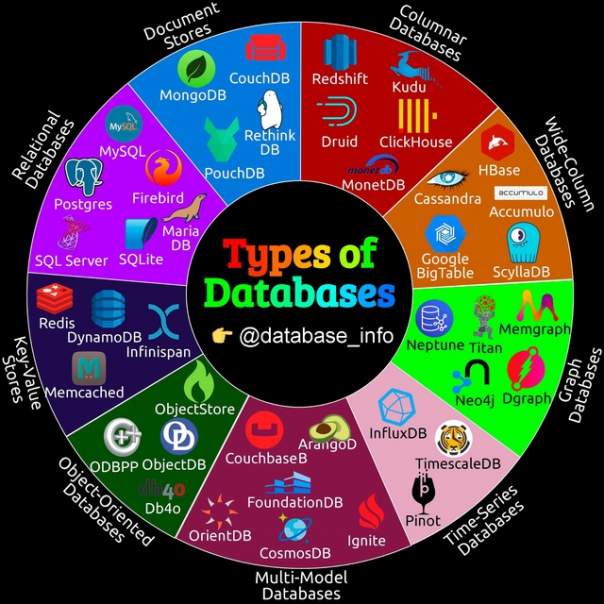
Базы данных классифицируются в первую очередь по методу организации данных, способу их поиска и хранения, производительности при доступе к данным и способности распределять данные по нескольким узлам для повышения доступности и устойчивости
#db
? @itmozg
22 Aug в 17:30
Облачные базы данных: Шпаргалка
В современном мире, основанном на данных, выбор правильной базы данных имеет решающее значение и в то же время сложен. Сейчас облако предлагает больше возможностей для структурированных, полуструктурированных и неструктурированных баз данных, чем когда-либо. Эта шпаргалка поможет выбрать наиболее подходящую для ваших нужд.
Структурированные базы данных?
Структурированные базы данных организуют данные в предопределенные схемы и модели.
Реляционные базы данных, такие как MySQL и PostgreSQL, хранят данные в таблицах со строками и столбцами.
Колоночные базы данных, такие как Amazon Redshift и Google BigQuery, также имеют структурированную модель данных, но хранят их по-другому, оптимизируя для аналитических запросов.
Преимущества:
- Эффективные SQL-запросы
- Возможность применения ограничений и валидации
- Последовательность там, где это необходимо
Примеры использования: CRM-системы, управление запасами, бухгалтерский учет, аналитика
Полуструктурированные базы данных?
Полуструктурированные базы данных обеспечивают гибкость, храня данные без соблюдения формальной схемы. Данные часто хранятся в виде JSON или других гибких форматов.
Примеры включают в себя документ-базы данных, такие как MongoDB, графовые базы данных, наподобие Neptune, широкие колоночные хранилища, такие как ScyllaDB, и хранилища ключ-значение, такие как DynamoDB.
Преимущества:
- Гибкость для изменяющихся данных
- Масштабируемость на разных серверах
Примеры использования: Электронная коммерция, ленты социальных сетей, данные IoT
Неструктурированные базы данных?
Неструктурированные базы данных оптимизированы для хранения и обработки огромных объемов разнородных данных, таких как документы, изображения, видео. Примеры: AWS S3, Azure Blob Storage.
Преимущества:
- Хранение огромных объемов данных
- Высокая масштабируемость
Примеры использования: Медиарепозитории, управление контентом, океаны данных, журнальные данные, резервное копирование.
#db
? @itmozg

22 Aug в 17:30
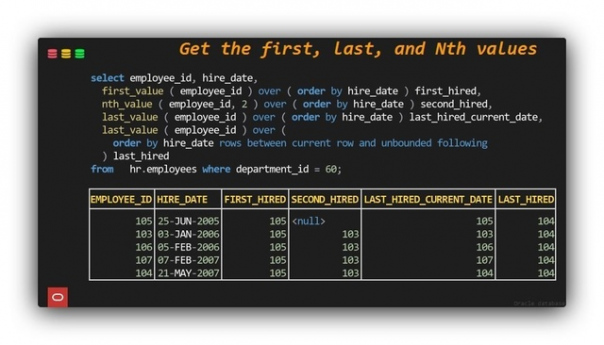
Находим первое, N-ое или последнее значение в SQL
FIRST_VALUE ( val ) - Start val
NTH_VALUE ( val, N ) - Val at row N
LAST_VALUE ( val ) - Final val
Условие OVER определяет порядок
Будьте осторожны с использованием значения по умолчанию - оно останавливает NTH и LAST на текущем значении => неожиданные результаты
#db #sql
? @itmozg
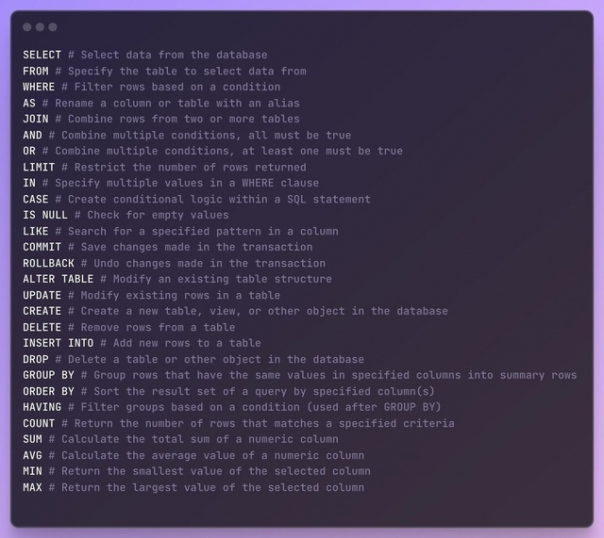
19 Aug в 16:10
Команды SQL - основы
#db
? @itmozg
19 Aug в 16:10
Как базы данных выполняют SQL-запросы?
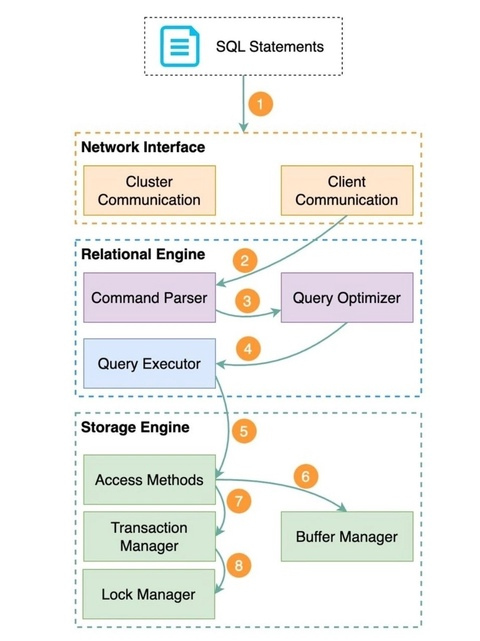
Процесс выполнения SQL-запросов в базе данных включает в себя несколько компонентов, взаимодействующих между собой. Хотя конкретная архитектура различных систем баз данных может отличаться, ниже описана общая последовательность действий.
1. Оператор SQL запускается в клиентской программе и передается по сети на сервер базы данных.
2. Когда сервер базы данных получает SQL-оператор, реляционный движок начинает его обработку. Сначала синтаксический анализатор проверяет правильность оператора. Затем он преобразует оператор в дерево запросов, которое представляет собой внутреннюю структуру данных.
3. Оптимизатор запросов просматривает дерево запросов и определяет наиболее эффективный способ выполнения SQL-оператора, создавая план выполнения.
4. План выполнения передается исполнителю запроса, который использует его для координации получения или изменения данных в соответствии с запросом SQL. Для доступа к данным исполнитель взаимодействует с движком хранилища.
5. Движок хранилища использует методы доступа - протоколы чтения и записи данных, наиболее эффективные для выполнения различных операций.
6. При чтении данных менеджер буферов проверяет, кэшированы ли нужные данные в памяти, и при необходимости извлекает их с диска. Это ускоряет последующий доступ.
7. При записи данных со вставкой или обновлением менеджер транзакций следит за тем, чтобы изменения происходили атомарно и сохраняли целостность базы данных.
8. В то же время менеджер блокировок накладывает блокировки, чтобы несколько транзакций могли выполняться одновременно, не конфликтуя между собой. Таким образом, обеспечивается изоляция и согласованность.
Работая вместе, эти компоненты обеспечивают надежную и эффективную обработку SQL-запросов в системе управления базами данных.
? @itmozg