2 Sep в 07:00
Советы по Spring ?
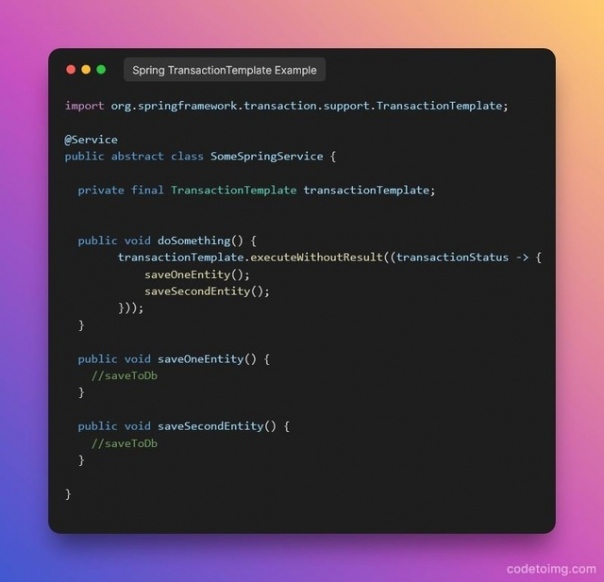
Чтобы выполнять действия в транзакции базы данных, вы можете использовать шаблон Spring TransactionTemplate вместо @ Transactional
? @bookflow
Другие записи сообщества
2 Oct в 11:50
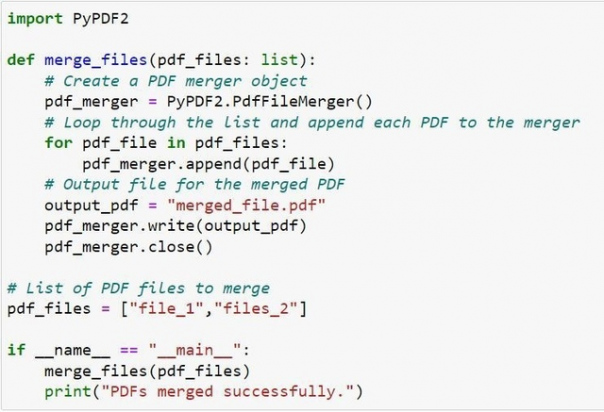
Объединение PDF-файлов с помощью PyPDF2
Установите библиотеку с помощью pip.
pip install PyPDF2
Вы можете легко объединить PDF-файлы, используя приведенный ниже код. Просто замените имена в списке pdf-файлов на имена pdf-файлов, которые вы хотите объединить (если они находятся в том же каталоге, что и ваш Python-скрипт), или на ссылки на pdf-файлы.
import PyPDF2
def merge files (pdf files: list):
# Create a PDF merger obiect
pdf merger = PyPDF2.PdfFileMerger ()
# Loop through the list and append each PDF to the merger
for pdf_file in pdf_files:
pdf_merger.append(pdf_file)
# Output file for the merged PDF
output_pdf = "merged_file.pdf"
pdf_merger.write(output_pdf)
pdf_merger.close()
# List of PDF files to merge
pdf_files = @Bookflow
27 Sep в 18:20
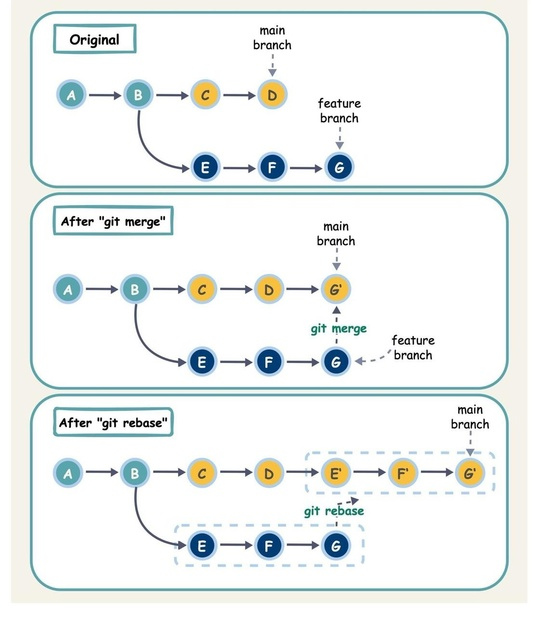
Git Merge vs. Rebase vs. Squash Commit
В чем разница?
Когда мы объединяем изменения из одной ветки Git в другую, мы можем использовать «git merge» или «git rebase». Диаграмма ниже показывает, как работают эти две команды.
Git Merge
Эта команда создает новый коммит G’ в основной ветке. G’ связывает историю обеих веток: основной и функциональной.
Git merge — это недеструктивная операция. Она добавляет новый коммит в основную ветку, не изменяя существующие коммиты в обеих ветках.
Git Rebase
Git rebase переносит историю коммитов функциональной ветки на конец основной ветки. Он создает новые коммиты E’, F’ и G’ для каждого коммита в функциональной ветке.
Преимущество rebase в том, что он создает линейную историю коммитов.
Однако будьте осторожны: следуйте золотому правилу Git Rebase — никогда не используйте его на общих ветках, чтобы избежать путаницы среди ваших коллег.
Git Squash Commit
Сквошинг сжимает несколько коммитов в один, упрощая историю коммитов.
?@Bookflow
27 Sep в 18:20
Облачные базы данных: Шпаргалка
В современном мире, основанном на данных, выбор правильной базы данных имеет решающее значение и в то же время сложен. Сейчас облако предлагает больше возможностей для структурированных, полуструктурированных и неструктурированных баз данных, чем когда-либо. Эта шпаргалка поможет выбрать наиболее подходящую для ваших нужд.
Структурированные базы данных?
Структурированные базы данных организуют данные в предопределенные схемы и модели.
Реляционные базы данных, такие как MySQL и PostgreSQL, хранят данные в таблицах со строками и столбцами.
Колоночные базы данных, такие как Amazon Redshift и Google BigQuery, также имеют структурированную модель данных, но хранят их по-другому, оптимизируя для аналитических запросов.
Преимущества:
- Эффективные SQL-запросы
- Возможность применения ограничений и валидации
- Последовательность там, где это необходимо
Примеры использования: CRM-системы, управление запасами, бухгалтерский учет, аналитика
Полуструктурированные базы данных?
Полуструктурированные базы данных обеспечивают гибкость, храня данные без соблюдения формальной схемы. Данные часто хранятся в виде JSON или других гибких форматов.
Примеры включают в себя документ-базы данных, такие как MongoDB, графовые базы данных, наподобие Neptune, широкие колоночные хранилища, такие как ScyllaDB, и хранилища ключ-значение, такие как DynamoDB.
Преимущества:
- Гибкость для изменяющихся данных
- Масштабируемость на разных серверах
Примеры использования: Электронная коммерция, ленты социальных сетей, данные IoT
Неструктурированные базы данных?
Неструктурированные базы данных оптимизированы для хранения и обработки огромных объемов разнородных данных, таких как документы, изображения, видео. Примеры: AWS S3, Azure Blob Storage.
Преимущества:
- Хранение огромных объемов данных
- Высокая масштабируемость
Примеры использования: Медиарепозитории, управление контентом, океаны данных, журнальные данные, резервное копирование.
? @Bookflow
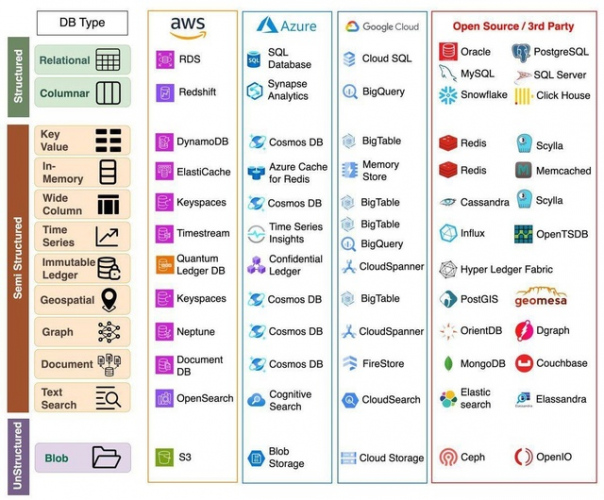
10 Sep в 11:41
Логирование, трассировка и метрики — это три столпа наблюдаемости системы.
На диаграмме ниже представлены их определения и типичные архитектуры.
? Логирование
Логирование записывает дискретные события в системе. Например, можно зафиксировать входящий запрос или обращение к базе данных как события. Логирование имеет наибольший объем данных. Стек ELK (Elastic-Logstash-Kibana) часто используется для построения платформы анализа логов. Обычно мы определяем стандартизированный формат логирования для различных команд, чтобы можно было использовать ключевые слова при поиске среди большого количества логов.
? Трассировка
Трассировка обычно ориентирована на запросы. Например, пользовательский запрос проходит через API-шлюз, балансировщик нагрузки, сервис A, сервис B и базу данных, что может быть визуализировано в системах трассировки. Это полезно при попытках выявить узкие места в системе. Мы используем OpenTelemetry для демонстрации типичной архитектуры, объединяющей три столпа в единую структуру.
? Метрики
Метрики обычно представляют собой агрегируемую информацию из системы. Например, QPS сервиса, отзывчивость API, задержка сервиса и т.д. Исходные данные записываются в базы данных временных рядов, такие как InfluxDB. Prometheus извлекает данные и преобразует их на основе предопределенных правил оповещения. Затем данные отправляются в Grafana для отображения или в менеджер оповещений, который затем рассылает уведомления или предупреждения по электронной почте, SMS или в Slack.
? @bookflow
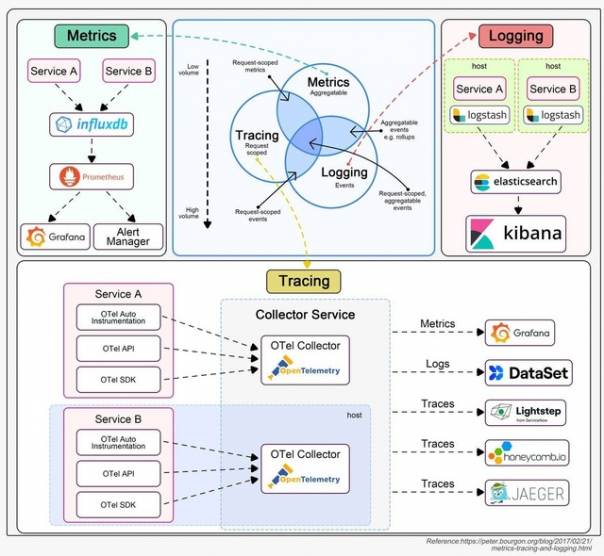
3 Sep в 07:40
Нас часто просят разрабатывать системы с высокой доступностью, масштабируемостью и пропускной способностью. Что это именно означает?
Ниже приведена шпаргалка по проектированию систем с распространенными решениями.
1. Высокая доступность
Это означает необходимость обеспечения высокого уровня времени работы. Обычно мы описываем целевой уровень дизайна как «3 девятки» или «4 девятки». «4 девятки» (99,99% времени работы) означает, что сервис может быть недоступен только 8,64 секунды в день.
Для достижения высокой доступности необходимо спроектировать систему с избыточностью. Существуют несколько способов сделать это:
- Горячий-горячий: два экземпляра получают один и тот же ввод и отправляют вывод в downstream-сервис. Если одна из сторон недоступна, другая сторона может сразу же взять на себя ее функции. Поскольку обе стороны отправляют вывод в downstream, downstream-система должна выполнять дедупликацию.
- Горячий-теплый: два экземпляра получают один и тот же ввод, но только горячая сторона отправляет вывод в downstream-сервис. Если горячая сторона недоступна, теплая сторона берет на себя функции и начинает отправлять вывод в downstream-сервис.
- Кластер с единственным лидером: один лидер получает данные от upstream-системы и реплицирует их на другие реплики.
- Кластер без лидера: в таком кластере нет лидера. Любая запись будет реплицироваться на другие экземпляры. Пока количество экземпляров для записи плюс количество экземпляров для чтения больше общего числа экземпляров, мы должны получать корректные данные.
2. Высокая пропускная способность
Это означает, что сервис должен обрабатывать большое количество запросов за определенный период времени. Обычно используются метрики QPS (запросов в секунду) или TPS (транзакций в секунду).
Для достижения высокой пропускной способности часто добавляются кэши в архитектуру, чтобы запросы могли возвращаться без обращения к медленным устройствам ввода-вывода, таким как базы данных или диски. Также можно увеличить количество потоков для вычислительно интенсивных задач. Однако добавление слишком большого количества потоков может ухудшить производительность. В таком случае необходимо определить узкие места в системе и увеличить ее пропускную способность. Использование асинхронной обработки может эффективно изолировать ресурсоемкие компоненты.
3. Высокая масштабируемость
Это означает, что система может быстро и легко расширяться, чтобы справляться с большим объемом (горизонтальная масштабируемость) или добавлением новых функциональностей (вертикальная масштабируемость). Обычно мы отслеживаем время отклика, чтобы решить, нужно ли масштабировать систему.
? @bookflow
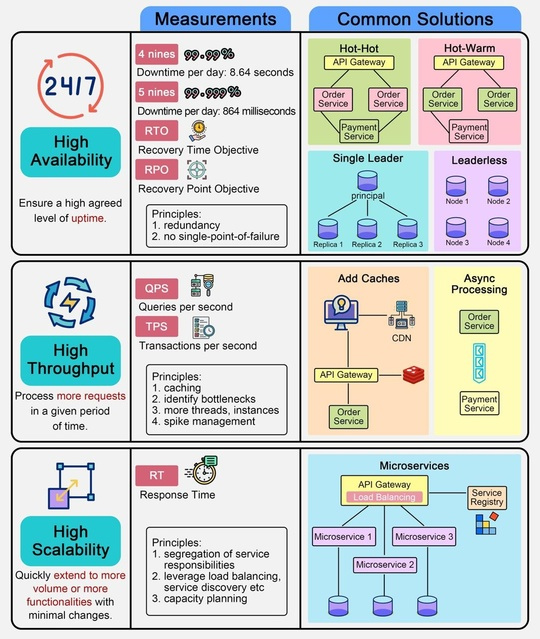
9 Aug в 14:30
Порядок выполнения SQL-запросов
?@Bookflow
2 Aug в 11:30
Советы по Javascript ?
? @bookflow

2 Aug в 11:30
Дети, которые запускали дефрагментатор windows и сидели, глядя на маленькие квадратики, меняющие цвет, теперь программисты ?
?@Bookflow
26 Jul в 20:20
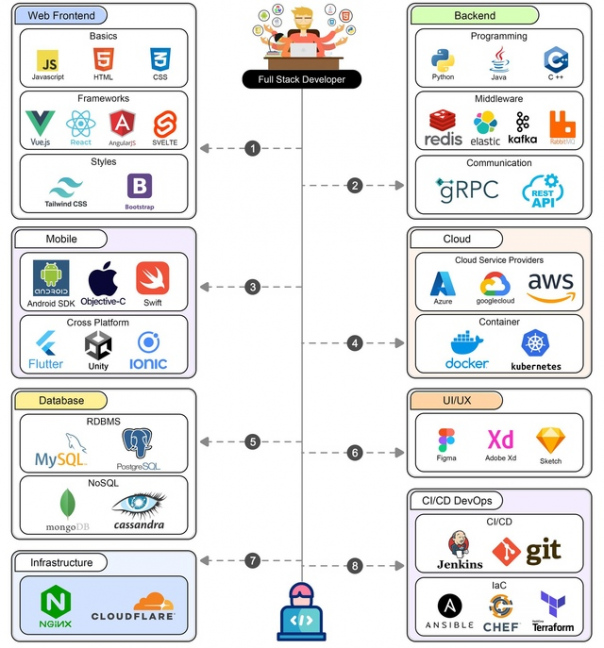
Дорожная карта Full-Stack разработчика
Full-stack разработчик должен владеть широким спектром технологий и инструментов в различных областях разработки программного обеспечения. Здесь представлен полный обзор технических стеков, необходимых для разработчика полного стека.
? 1. Фронтенд разработчик
Frontend-разработка включает в себя создание пользовательского интерфейса и пользовательского опыта веб-приложения.
? 2. Бэкенд разработчик
Разработка бэкенда включает в себя управление логикой на стороне сервера, базами данных и интеграцию различных сервисов.
? 3. Разработка баз данных
Разработка баз данных включает в себя управление хранением, поиском и обработкой данных.
? 4. Мобильная разработка
Мобильная разработка подразумевает создание приложений для мобильных устройств.
? 5. Облачные вычисления
Облачные вычисления подразумевают развертывание и управление приложениями на облачных платформах.
? 6. UI/UX дизайн
UI/UX-дизайн включает в себя разработку пользовательского интерфейса и опыта работы с приложениями.
? 7. Инфраструктура и DevOps
Инфраструктура и DevOps включают в себя управление инфраструктурой, развертывание и непрерывную интеграцию/непрерывную доставку (CI/CD) приложений.
?@Bookflow
24 Jul в 16:40
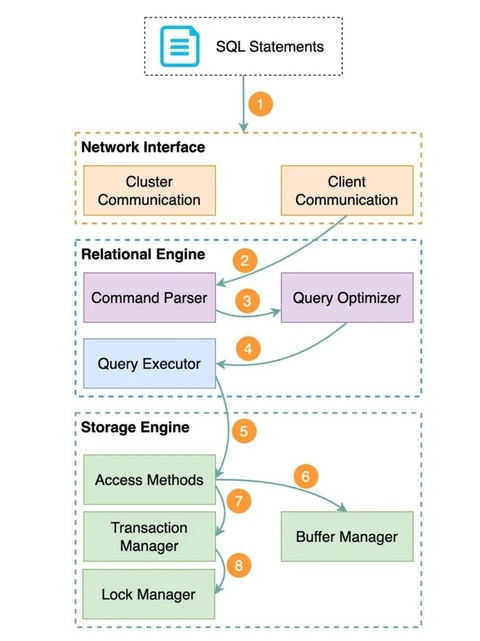
Как базы данных выполняют SQL-запросы?
Процесс выполнения SQL-запросов в базе данных включает в себя несколько компонентов, взаимодействующих между собой. Хотя конкретная архитектура различных систем баз данных может отличаться, ниже описана общая последовательность действий.
1. Оператор SQL запускается в клиентской программе и передается по сети на сервер базы данных.
2. Когда сервер базы данных получает SQL-оператор, реляционный движок начинает его обработку. Сначала синтаксический анализатор проверяет правильность оператора. Затем он преобразует оператор в дерево запросов, которое представляет собой внутреннюю структуру данных.
3. Оптимизатор запросов просматривает дерево запросов и определяет наиболее эффективный способ выполнения SQL-оператора, создавая план выполнения.
4. План выполнения передается исполнителю запроса, который использует его для координации получения или изменения данных в соответствии с запросом SQL. Для доступа к данным исполнитель взаимодействует с движком хранилища.
5. Движок хранилища использует методы доступа - протоколы чтения и записи данных, наиболее эффективные для выполнения различных операций.
6. При чтении данных менеджер буферов проверяет, кэшированы ли нужные данные в памяти, и при необходимости извлекает их с диска. Это ускоряет последующий доступ.
7. При записи данных со вставкой или обновлением менеджер транзакций следит за тем, чтобы изменения происходили атомарно и сохраняли целостность базы данных.
8. В то же время менеджер блокировок накладывает блокировки, чтобы несколько транзакций могли выполняться одновременно, не конфликтуя между собой. Таким образом, обеспечивается изоляция и согласованность.
Работая вместе, эти компоненты обеспечивают надежную и эффективную обработку SQL-запросов в системе управления базами данных.
? @bookflow