
11 Apr в 22:20
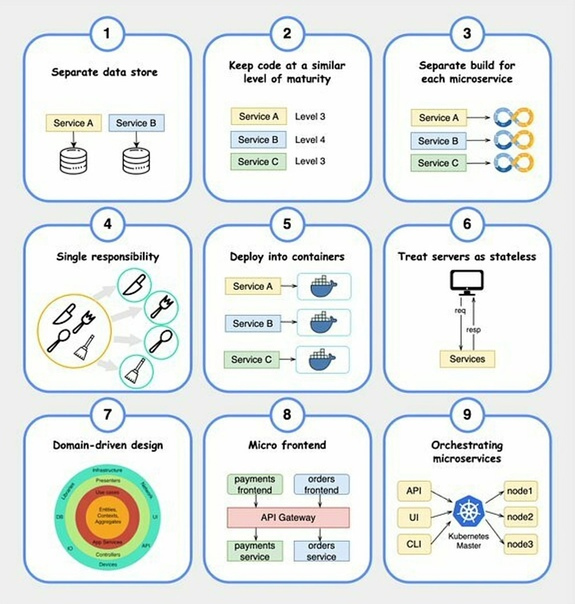
9 лучших практик разработки микросервисов
Другие записи сообщества
26 May в 19:30
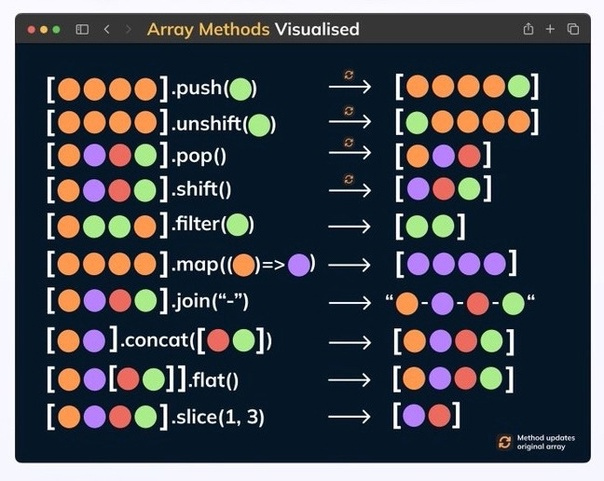
Визуализация методов массивов JavaScript ??
? @bookflow
19 May в 02:20
Шпаргалка по python
? @bookflow










30 Apr в 19:20
Шпаргалка по HTML input types

26 Apr в 08:30
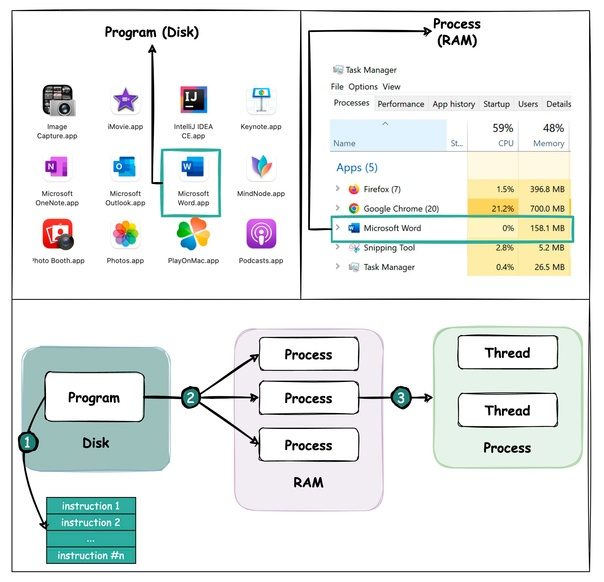
Популярный вопрос на собеседовании: В чем разница между Process и Thread?
Чтобы лучше понять этот вопрос, давайте сначала разберемся, что такое программа. Программа - это исполняемый файл, содержащий набор инструкций и пассивно хранящийся на диске. Одна программа может иметь несколько процессов. Например, браузер Chrome создает отдельный процесс для каждой отдельной вкладки.
Процесс означает, что программа находится в процессе выполнения. Когда программа загружается в память и становится активной, она превращается в процесс. Процессу требуются некоторые важные ресурсы, такие как регистры, счетчик программ и стек.
Поток - это наименьшая единица выполнения в рамках процесса.
? Взаимосвязь между программой, процессом и потоком:
? Программа содержит набор инструкций.
? Программа загружается в память. Она становится одним или несколькими выполняющимися процессами.
? Когда процесс запускается, ему выделяются память и ресурсы. Процесс может иметь один или несколько потоков.
? Основные различия между процессом и потоком:
? Процессы обычно независимы, в то время как потоки существуют как подмножества процесса.
? Каждый процесс имеет собственное пространство памяти. Потоки, принадлежащие одному процессу, делят одну и ту же память.
? Процесс — это тяжеловесная операция. На его создание и завершение требуется больше времени.
? Переключение контекста между процессами более дорогостоящее.
? @bookflow
20 Apr в 10:50
Совет по Javascript ?
Знаете ли вы о способе копирования массива с заменой одного элемента?

6 Apr в 05:10
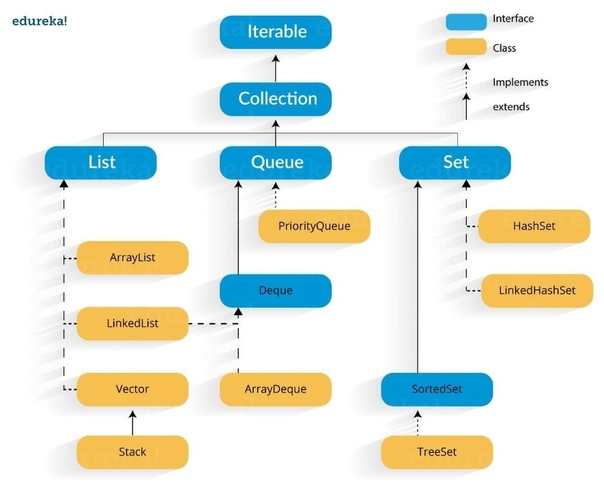
? Java Collections


4 Apr в 06:50
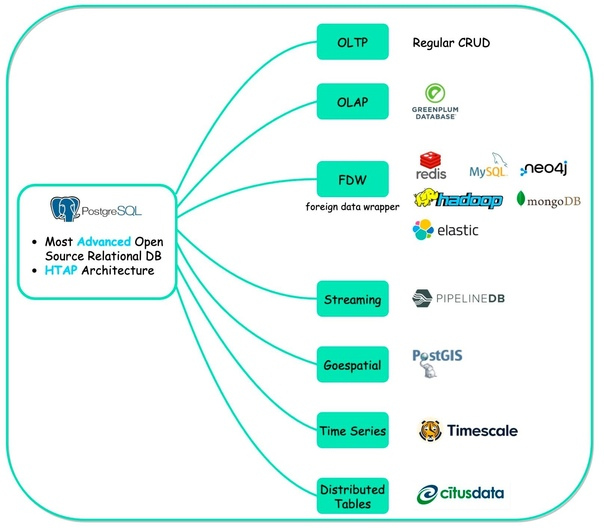
Почему PostgreSQL признан самым лбимой бд по результатам опроса разработчиков Stackoverflow?
На диаграмме показано множество вариантов использования PostgreSQL - одной базы данных, которая включает в себя почти все функции необходимых разработчикам.
?OLTP (Online Transaction Processing)
Мы можем использовать PostgreSQL для CRUD-операций (Create-Read-Update-Delete).
?OLAP (Online Analytical Processing)
Мы можем использовать PostgreSQL для аналитической обработки. PostgreSQL основан на архитектуре ???? (Hybrid transactional/analytical processing), поэтому он может хорошо работать как с OLTP, так и с OLAP.
?FDW (Foreign Data Wrapper)
FDW - это расширение, доступное в PostgreSQL, которое позволяет нам обращаться к таблице или схеме одной базы данных из другой.
?Streaming
PipelineDB - это расширение PostgreSQL для высокопроизводительной агрегации временных рядов, предназначенное для работы с отчетами и аналитическими приложениями в реальном времени.
?Geospatial
PostGIS - это расширитель базы данных для объектно-реляционной базы данных PostgreSQL. Он добавляет поддержку географических объектов, позволяя выполнять запросы на определение местоположения в SQL.
?Временные ряды
Timescale расширяет PostgreSQL для работы с временными рядами и аналитикой. Например, разработчики могут объединять непрерывные потоки финансовых и тиковых данных с другими бизнес-данными для создания новых приложений и получения уникальных знаний.
?Распределенные таблицы
CitusData масштабирует Postgres за счет распределения данных и запросов.
1 Apr в 07:41
Шпаргалка по оконным функциям в SQL


16 Mar в 11:40
Облачные базы данных: Шпаргалка
В современном мире, основанном на данных, выбор правильной базы данных имеет решающее значение и в то же время сложен. Сейчас облако предлагает больше возможностей для структурированных, полуструктурированных и неструктурированных баз данных, чем когда-либо. Эта шпаргалка поможет выбрать наиболее подходящую для ваших нужд.
Структурированные базы данных?
Структурированные базы данных организуют данные в предопределенные схемы и модели.
Реляционные базы данных, такие как MySQL и PostgreSQL, хранят данные в таблицах со строками и столбцами.
Колоночные базы данных, такие как Amazon Redshift и Google BigQuery, также имеют структурированную модель данных, но хранят их по-другому, оптимизируя для аналитических запросов.
Преимущества:
- Эффективные SQL-запросы
- Возможность применения ограничений и валидации
- Последовательность там, где это необходимо
Примеры использования: CRM-системы, управление запасами, бухгалтерский учет, аналитика
Полуструктурированные базы данных?
Полуструктурированные базы данных обеспечивают гибкость, храня данные без соблюдения формальной схемы. Данные часто хранятся в виде JSON или других гибких форматов.
Примеры включают в себя документ-базы данных, такие как MongoDB, графовые базы данных, наподобие Neptune, широкие колоночные хранилища, такие как ScyllaDB, и хранилища ключ-значение, такие как DynamoDB.
Преимущества:
- Гибкость для изменяющихся данных
- Масштабируемость на разных серверах
Примеры использования: Электронная коммерция, ленты социальных сетей, данные IoT
Неструктурированные базы данных?
Неструктурированные базы данных оптимизированы для хранения и обработки огромных объемов разнородных данных, таких как документы, изображения, видео. Примеры: AWS S3, Azure Blob Storage.
Преимущества:
- Хранение огромных объемов данных
- Высокая масштабируемость
Примеры использования: Медиарепозитории, управление контентом, океаны данных, журнальные данные, резервное копирование.

7 Mar в 05:30
⚡️ Совет по работе с базами данных ?
Иногда вы хотите сделать столбцы уникальными, но не можете сделать это, потому что, например, в таблице все еще существуют строки, помеченные как удаленные, с тем же значением. Тем не менее, вы можете создать это ограничение, включив только неудаленные строки.
