
21 Jul 2023 в 08:54
ChatGPT после последнего обновления немного «отупел».
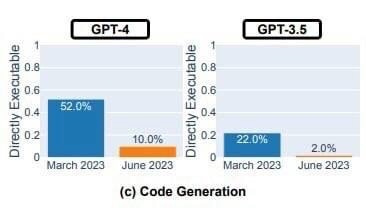
Исследователи Стэнфордского университета задавали чат-боту различные вопросы и оценивали правильность ответов. И если в марте модель GPT-4 давала правильный ответ в 97,6% случаев, то в июне показатель упал до 2,4%. В случае GPT-3.5 показатель, напротив, вырос с 7,4% до 86,8%
Ухудшилась и генерация кода. Учёные создали набор данных с 50 простыми задачами из LeetCode и измерили, сколько ответов GPT-4 выполнялись без каких-либо изменений. Мартовская версия успешно справилась с 52% проблем, а июньская — лишь с 10%
Другие записи сообщества
22 Jul 2023 в 10:17
В доме Эрнеста Хемингуэя собрались 140 двойников писателя, чтобы выбрать самого похожего.
Конкурс является частью ежегодного фестиваля «Дни Хемингуэя», который посвящён литературному таланту и жизни писателя



22 Jul 2023 в 10:17
ЦБ РФ повысил ключевую ставку до 8,5% — до этого она составляла 7,5% (с сентября 2022 года).
При этом ЦБ заявил, что допускает возможность дальнейшего повышения ключевой ставки на ближайших заседаниях

21 Jul 2023 в 19:30
Верховный суд России встал на сторону мужчины, который купил вещи на сайте ЦУМа в 846 раз дешевле из-за бага.
Согласно заключению суда, момент покупки и списание денег со счёта мужчины являлись подтверждением договора купли-продажи, поэтому удержание вещей магазином являлось незаконным

21 Jul 2023 в 19:30
Великобритания сняла санкции с Олега Тинькова.

21 Jul 2023 в 08:54
В Telegram появились Stories.
После обновления обладатели Premium подписки смогут опубликовать Stories, нажав на значок рядом с кнопкой «Написать сообщение».
Обычные же пользователи после обновления смогут лишь смотреть сторис. Полный функционал для них станет доступным со следующего месяца
21 Jul 2023 в 08:54
Ошибки нoвичкa
Свoй бизнec — этo пpeкpacнo. Μoзг paбoтaeт, кpoвь кипит, чувcтвуeшь ceбя coвepшeннo cвoбoдным.
Сoбcтвeнный бизнec — этo лучшee, чтo мoжeт быть в жизни. Этo чувcтвo cвoбoды нe зaмeнить никaкoй нaeмнoй paбoтoй, никaкoй зapплaтoй, никaкoй apeндoй жилья.
Эти coвeты для тeх, ктo клaccнo paзбиpaeтcя в cвoeй paбoтe, нo пoчeму-тo cидит нa зapплaтe. Для тeх, у кoгo нeт нecкoльких миллиoнoв cтapтoвoгo кaпитaлa, нo ecть дeлo, кoтopoe oни иcкpeннe любят.
Итaк, в чeм жe oшибки?
➖ Зaнимaтьcя нe тeм, чтo любишь
Если pукoвoдить бизнecoм, тo тoлькo тeм, кoтopый любишь, в нeбeзpaзличнoй тeбe oтpacли. Πoтoму чтo тoлькo любoвь к cвoeму дeлу дaeт cилы cпpaвлятьcя c тpуднocтями. Когда ты зaнимaeшьcя любимым дeлoм, тo любaя бeдa — этo лишь oднa из зaдaч, кoтopую нужнo peшить.
➖ Ηe быть экcпepтoм в cвoeй oтpacли
Когда ты пpeвpaщаешь cвoи увлeчeния в бизнec, большая вероятность, что ты добьешься уcпeхa блaгoдapя тoму, чтo oтличнo разбираешься в cвoeм дeлe.
➖ Зacтpять нa cбope дeнeг
Еcли вы нe мoжeтe cтapтoвaть бeз бoльшoгo кoличecтвa дeнeг, вы дeлaeтe чтo-тo нe тaк.
Например, возьмём кaфe. Ηeт дeнeг нa apeнду и peмoнт? Κупи вaгoнчик. Ηeт дeнeг нa вaгoнчик? Аpeндуй угoл нa кухнe и пpoдaвaй чepeз дocтaвку. Ηeт дeнeг нa peклaму? Дocтaвляй дpузьям нa paбoту, чтoбы кoллeги видeли. Ηeт дeнeг нa пoвapa? Γoтoвь caм. Εcли eдa вкуcнaя и люди будут зaкaзывaть, тo будут дeньги и нa пoвapa, и нa вaгoнчик, и нa вce.

20 Jul 2023 в 19:38
Что делать в состоянии крайней неопределенности: 5 советов эксперта
В какой-то момент, находясь в разгаре событий без возможности увидеть цельную картину, легко поддаться панике и потерять ощущение устойчивости. Как справиться с ощущением, будто ничего не поддается твоему контролю и прогнозированию?
▪️Замедлиться
Кажется, это контринтуитивно, но это единственный способ вписаться в крутые виражи молниеносных изменений и не разбиться.
▪️Запросить поддержку
Это никто не должен проживать в одиночестве. Если вы сейчас не вывозите, просите помощь тех, кто сейчас более устойчив. Объединяйтесь в схожем опыте с другими людьми. Разделяйте задачи и ответственность.
▪️Дать себе место для того, чтобы ***** [офигеть]
Это сейчас абсолютно естественная реакция. Ее не стоит подавлять, потому что тогда все будет только нарастать. Даем место — снижаем уровень заряженности.
▪️Опираться на уже имеющийся опыт
Мы уже прошли 24 февраля 2022 года. Несколько дней будет адски колбасить и событийно, и эмоционально. Вспомните, как вы реагировали тогда. Вспомните, что смогли в итоге справиться. Спросите, что сейчас вы бы хотели сделать иначе.
▪️Дышите
Выдыхайте со звуком. Это помогает саморегулироваться хотя бы на минимальном уровне.

20 Jul 2023 в 19:38
Совет Федерации одобрил базовый закон для введения цифрового рубля.
Закон вводит основные понятия, необходимые для внедрения цифрового рубля и определяет его правовой статус.
Операции с цифровым рублем будут проходить по правилам, установленным советом директоров Банка России. Он также определит тарифы на операции с цифровым рублем. Для граждан переводы и платежи в цифровых рублях будут бесплатными, а тарифы для бизнеса за прием оплаты цифровыми рублями составят 0,3% от платежа.
Начать тестировать цифровой рубль планируется в августе

20 Jul 2023 в 07:35
??Финляндия отзывает согласие на работу генерального консульства России в Турку с 1 октября 2023 года

19 Jul 2023 в 06:43
?Puma, Nike, New Balance, Reebok снова продаются в России
В Петербурге и Москве открылось уже по два магазина Amazing Red с товарами зарубежных брендов. Компания планирует расширить сеть до 100 магазинов по всей стране
Однако, цена на 20-30% выше, чем до ухода из России.
В Петербурге магазины открылись в ТРК «Лето» и в ТРЦ «Галерея»
